
본 포스팅은 논문 3D Gaussian Splatting for real-time radiance field rendering 를 읽고 정리한 내용입니다.
아는 것이 많이 없어서 부족한 부분이 많습니다. 혹여나 틀린부분 있다면 지적해주시길 바랍니다!
제목: 3D Gaussian Splatting for real-time radiance field rendering
SIGGRAPH 2023에 게재된 논문이며, NeRF와 풀고자하는 문제는 같습니다.
여러 방향에서 촬영한 이미지와 카메라 pose 값이 주어지면 학습된 방향 이외에서 이미지를 생성하는 "View Synthesis"를 하는 task입니다.
다만 기존의 NeRF 방식과는 전혀 다르고, 기존의 다른 NeRF 알고리즘들에 비해 압도적인 성능(Rendering time, Training time, Quality)을 보여줍니다. (심지어 **딥러닝이 아님!)**
우선 전체 flowchart 입니다.
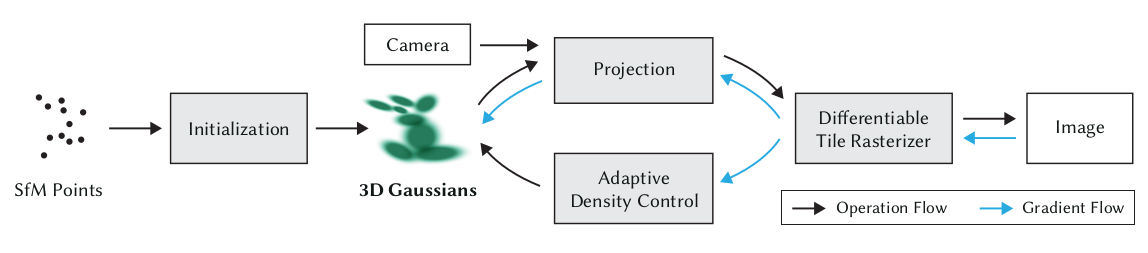
Initialization
SfM point를 gaussian으로 만듭니다. 이때 gaussian은 mean(position), covariance, $\alpha$(투명도), SH coefficient(색깔관련)의 파라미터를 각각 갖게 됩니다. 이 파라미터들은 optimization되는 파라미터입니다.
Projection
Gaussian을 2D로 projection 시킵니다.
Adaptive Density Control
Gaussian을 제거, 나누기, 복제를 합니다.
Differentiable Tile Rasterizer
Tile 기반의 rasterization을 해서 이미지를 만듭니다.
전체 과정을 정리하자면, 색깔과 투명도를 갖고 있는 gaussian들을 이용해서 이미지를 만들고, 만든 이미지와 input 이미지를 비교하여 loss 함수를 정의합니다.
그리고 이 loss 함수를 최소화 하는 방향으로 앞서 정의한 gaussian의 파라미터들(mean, covariance, $\alpha$, SH coefficient)을 최적화 시킵니다.
좀 더 자세히 보겠습니다.


Algorithm 1은 전체 과정을 보여줍니다. Algorithm 2은 algorithm 1에서 Rasterize 부분을 좀 더 자세히 설명하고 있습니다.
이 algorithm들을 하나하나 살펴보겠습니다.


SfM point들로부터 3D gaussian을 만듭니다.
M은 point들의 world coordinate 상의 3D 점의 위치입니다(mean 값). S는 covariance이며, 해당 점과 가장 가까운 세 점들과의 거리의 평균으로 초기화합니다. ( covariance는 gaussian의 모양을 결정합니다)
그러면 gaussian이 구(sphere)의 형태로 3D상에 존재하게 됩니다. 또한, 이 모든 gaussian들에 색깔 파라미터 C(SH coefficient)와 투명도 A 파라미터를 부여하게 됩니다.

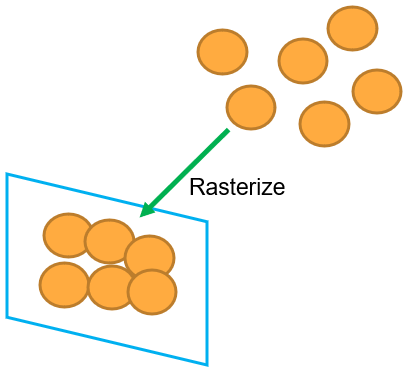
While문으로 들어가서 converge될 때까지 반복됩니다.
Input 이미지와 그 이미지를 수집했을 때의 카메라 pose(V)를 가져옵니다. 그 다음 Rasterize를 통해서 생성한 gaussian들로 이미지를 만들고, 만든 이미지($I$)와 input 이미지간에 loss를 정의 합니다.
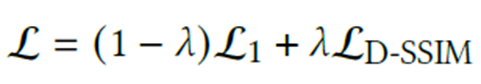
이 loss 함수가 최소화 되도록 back-propagation을 이용해 파라미터 M,S,C,A를 optimization 합니다. (그림은 극단적인 예시입니다)



Optimization 단계 이후, 일정 조건으로 gaussian들을 제거(remove)하거나 복제(clone), 분할(split)을 합니다.
조건은 다음과 같습니다.
- Gaussian의 투명도가 너무 작거나, gaussian의 크기가 너무 크다면(covariance 값이 크다면) 해당 gaussian을 제거합니다. 이미지를 만드는데에 불필요한 가우시안을 제거하는 과정입니다.
- Loss를 position에 대해 미분한 값(positional gradient $\nabla_pL$)이 일정 이상이면 densification을 수행합니다. 논문에서는 Gaussian이 어떤 영역을 너무 많이 커버하거나 너무 적게 커버하는 두 경우 모두가 공통적으로 positional gradient가 크다고 말합니다. 왜냐하면 두 경우 모두 gaussian이 reconstruction을 잘 구성하지 못하였으므로 loss가 많이 작아지는 방향(positional gradient가 큰 방향)으로 **gaussian의 position(mean)을 옮겨 주어야하기 때문입니다.**
그런데 그냥 옮기기만 하면 옮긴 후에는 또 빈 공간같은 reconstruction이 잘 되지 않는 영역이 생겨버리므로 gaussian의 갯수를 늘립니다.
해당 gaussian을 늘리기로 결정했다면, gaussian의 커버 영역에 따라 over, under reconstruction을 판별하여 어떻게 늘릴지 선택합니다.
- gaussian의 커버 영역 ||S||가 $\tau_s$보다 크면 over reconstruction을 했으므로 gaussian을 분할합니다. → 큰 gaussian을 쪼개므로 크기도 작아져야 합니다. 이때 1.6 scale로 나눠주게 되며 위치는 원래의 큰 gaussian의 PDF sampling으로 결정합니다.
- gaussian의 커버 영역 ||S||가 $\tau_s$ 보다 작으면 under reconstruction인 경우므로 gaussian을 복제합니다. → 해당 gaussian과 똑같이 만들고, 위치는 positional gradient의 방향으로 설정해줍니다.
그 후 iteration 횟수를 증가시킵니다.
전체 프로세스는 여기까지입니다. 이 후는 rasterize 함수 부분을 자세히 살펴보겠습니다.
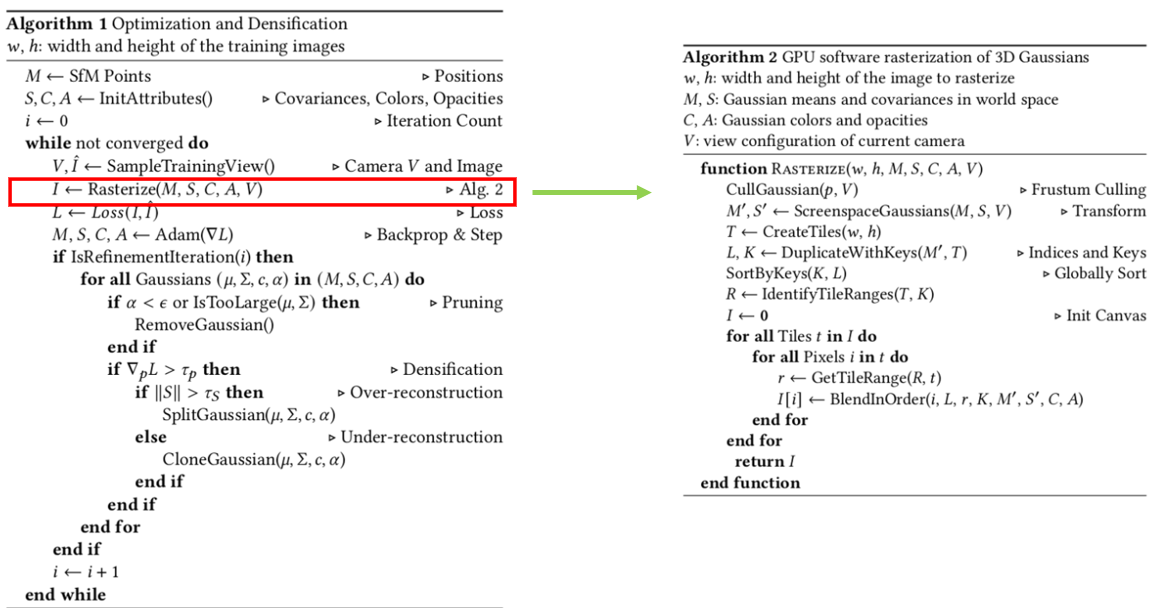

Cullgaussian의 기능은 3D world coordinate 상에 있는 모든 gaussian들 중에서 카메라 view frustum 안에 들어오는 gaussian들만 사용하게 됩니다.
그리고 사용할 gaussian들을 image plane으로 projection 시켜야 하기 때문에 3D world coordinate에 정의 되어 있는 gaussian들을 camera coordinate로 변환 시켜줍니다.
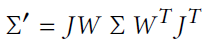
여기서 W 는 viewing transformation, J는 projective transformation의 affine approximation의 자코비안입니다.
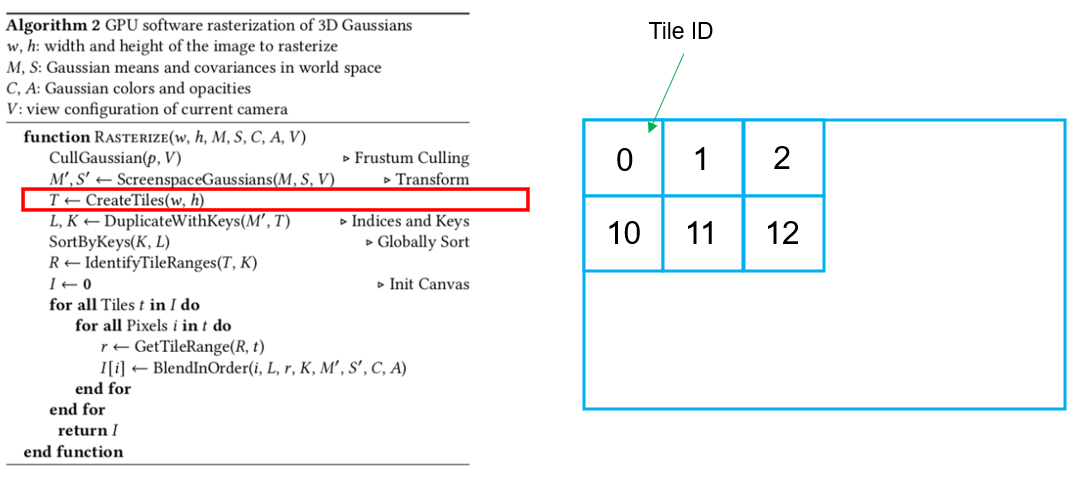
그 다음 tile을 w,h 사이즈 만큼 만듭니다. Tile의 사이즈는 16 x 16 pixel을 하나의 tile로 정의합니다.
그리고 tile 마다 각각의 ID를 부여합니다. 그림에서는 tile ID를 0, 1, 2, 10, 11, 12로 설명을 쉽게 하기위해 임의로 부여했습니다.
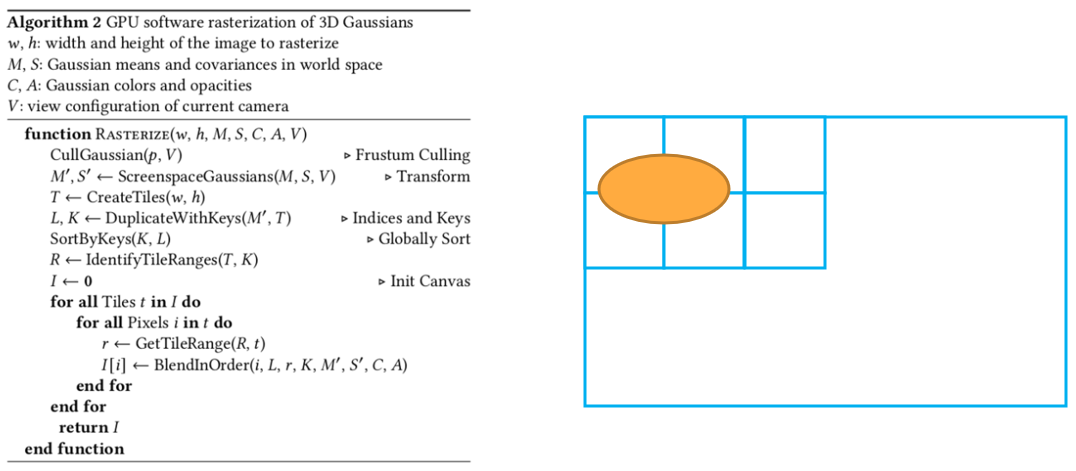
이제 하나의 gaussian을 image plane으로 projection 시켜봅니다. 만약 그림처럼 projection 된다면, gaussian은 tile ID 0, 1, 10, 11 총 4개의 tile들과 겹쳐있습니다.
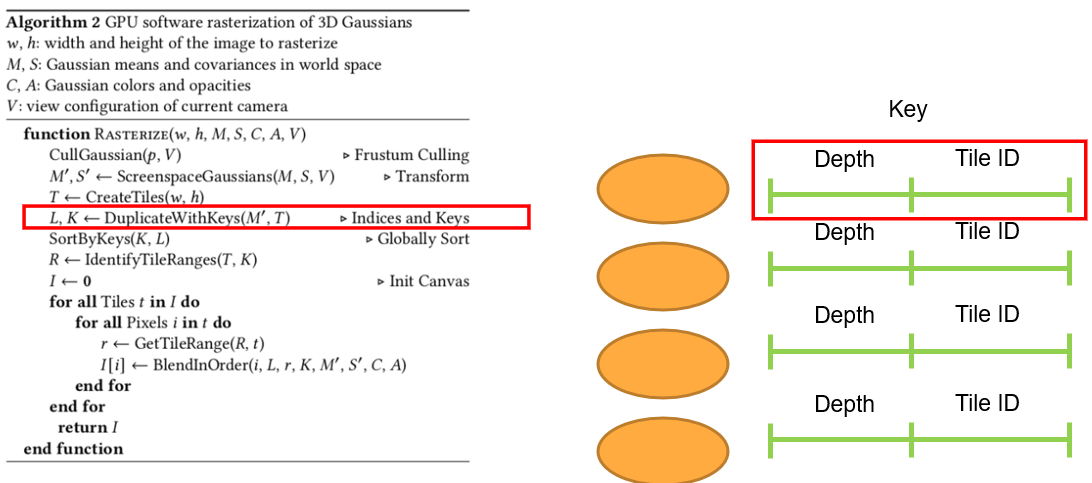
Projection 했던 gaussian을 projection 했을 때 겹친 타일의 수 만큼 복제합니다. 앞에서 tile ID 0, 1, 10, 11 총 4개의 tile과 겹쳐있으므로 같은 gaussian을 4개 복제합니다.
그리고 gaussian에 key를 만드는데, 이 key는 앞은 32bit depth, 뒤는 32bit tile ID로 구성되어 있으며, 4개의 gaussian의 key에는 각각 다른 tile ID들(겹쳤던 tile ID들)이 들어있습니다.
이러한 과정을 view frustum으로 선택했었던 모든 gaussian에 대해서 반복합니다.
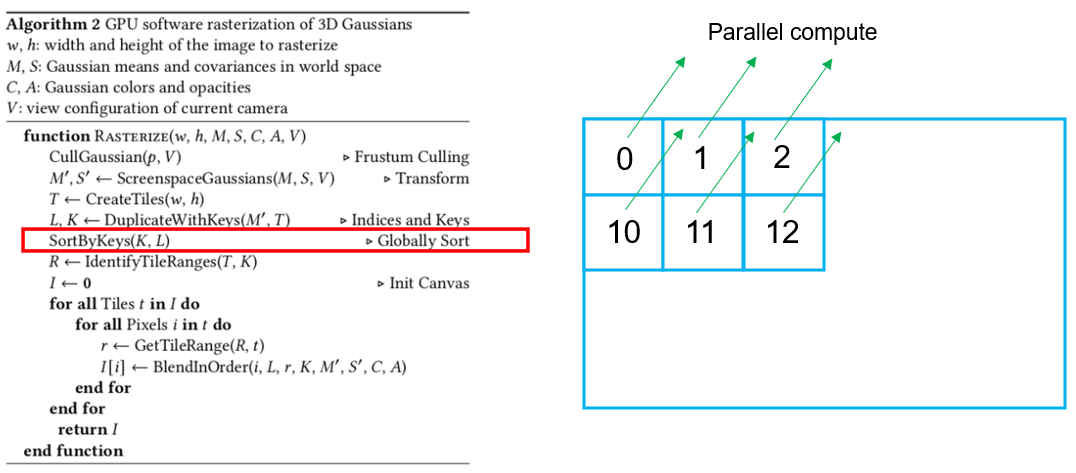
반복이 끝나면, 같은 tile ID를 갖는 gaussian들을 모아놓고, depth를 이용해 gaussian들을 정렬합니다. 이런 과정을 모든 tile들이 GPU를 이용해서 parallel하게 동작이 됩니다.
그리고 이런 일이 가능한 이유는, 같은 gaussian이라도 tile마다 같은 gaussian을 각각 갖고 있기 때문에(겹쳤던 tile마다 복제했기 때문) 가능합니다.

그리고 정렬한 guassian들을 이용해 depth의 range를 tile 마다 계산합니다.
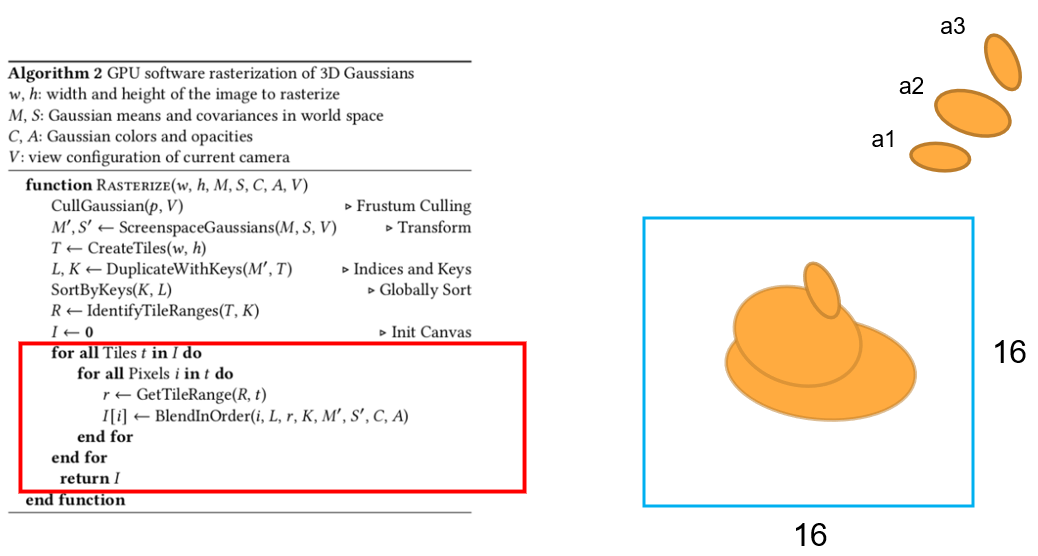
그리고 투명도(alpha)와 gaussian을 곱하면서 range안에 있는 gaussian들을 projection 시켜서 이미지를 rendering 합니다.
그리고 앞서 말했듯이 이렇게 만들어진 이미지와 input 이미지 간의 loss를 비교하여 loss가 적어지는 방향으로 gaussian들의 파라미터를 조정합니다.
Experiment

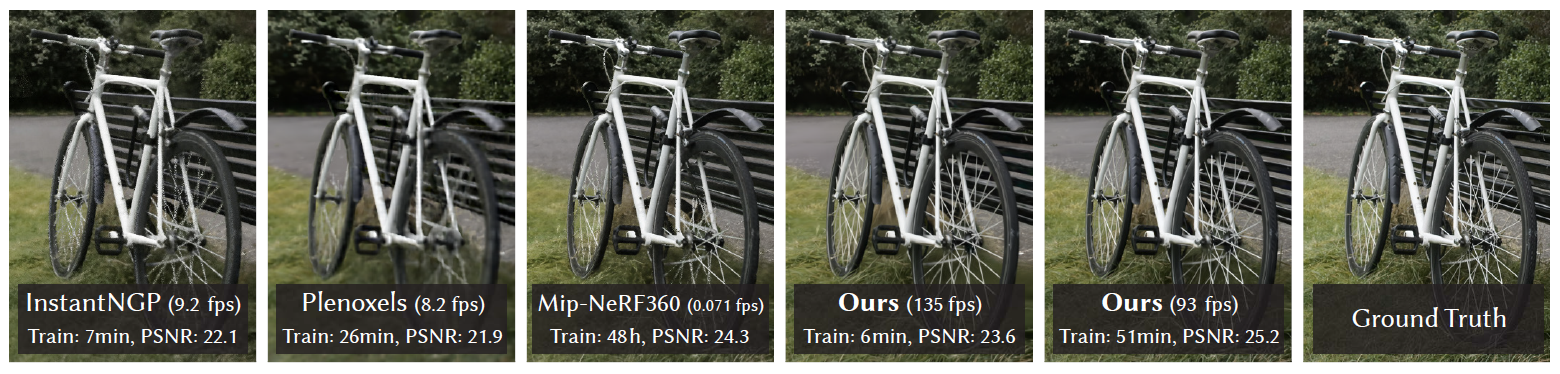
해당 논문의 알고리즘이 우수한 성능을 보임을 알 수 있습니다.
Limitaion
- 입력이미지가 부족한 scene에서는 artifact가 발생합니다.
- Regularization을 도입할 수 없지만, 만약 도입한다면 artifact 부분이나 보이지 않은 영역까지 잘 처리 할 수 있을 것입니다.
- 높은 GPU 메모리를 사용합니다. (최대 20GB 까지 사용함)
Closing
처음에는 생소한 용어들이나 개념들이 많아서 이해하는데 오래걸렸지만, 여러번 보다보니 어느정도 감은 잡히는 것 같습니다. 디테일 한건 코드를 참고해야 이해가 수월할듯 합니다.
NeRF와 비교 했을 때도 압도적인 성능이고, MLP도 사용하지 않으며 explicit하게 표현했다는게 놀랍습니다.
관심 분야가 SLAM인 만큼 3D gaussian splatting을 이용한 SLAM들도 리뷰 해보겠습니다.
'AI > 3DGS' 카테고리의 다른 글
| [3DGS] 3DGS Rasterization 코드와 함께 분석 (forward) (6) | 2024.09.17 |
|---|---|
| [3DGS] SplaTAM: Splat, Track & Map 3D Gaussians for Dense RGB-D SLAM [CVPR 2024] (2) | 2024.06.18 |
| [3DGS] Gaussian Splatting SLAM [CVPR 2024] (3) | 2024.06.17 |