
3D gaussian splatting에서 rasterization 부분을 코드와 함께 분석해보겠습니다.
실제 코드 안에는 많은 내용이 있지만 여기서는 일부만 설명하려고 합니다.
그리고 혹시나 틀린 부분이 있다면 알려주시길 바랍니다. (혼자 분석해서 부정확할 수 있음)
(3DGS에 대해 모르시는 분들은 이 글을 먼저 봐주세요!)
3DGS rasterization은 pytorch의 extension을 통해 빌드된 CUDA를 라이브러리처럼 불러와서 사용하게 되어 있습니다.
CUDA에서 병렬적으로 계산하기 때문에 rendering하고 파라미터를 빠르게 업데이트할 수 있다는 장점이 있습니다.
이번 글에서는 forward (gaussian으로 rendering 하는 부분) 파트를 리뷰 해보겠습니다.
먼저 gaussian 파라미터를 이용해 rendering하고 업데이트 하는 대략적인 과정은 다음과 같습니다.
Gaussians(python) --> Forward (CUDA) --> Buffer (Python) --> Backward (CUDA)
- Gaussians: Gaussian의 파라미터들 (Python에서 선언)
- Forward: Gaussian을 이용해 이미지를 rendering하는 부분입니다. (CUDA에서 계산)
- Buffer: Forward에서 계산한 정보를 버퍼에 저장합니다, 이는 backward에서 사용됩니다. (Python 이용)
- Backward: Gaussian parameter의 gradient를 구하는 과정입니다. (CUDA에서 계산)
Gaussians
3DGS에서 rendering 할 때 사용되는 파라미터는 다음과 같습니다.
- Position
- Color
- Opacity
- Scale
- Rotation
위의 파라미터들은 python에서 저장되어 있는 정보들인데, CUDA에서는 이 정보가 저장되어 있는 메모리의 시작주소를 읽어옵니다.
forward를 호출하는 코드
rendered = CudaRasterizer::Rasterizer::forward(
geomFunc,
binningFunc,
imgFunc,
P, degree, M,
background.contiguous().data<float>(),
W, H,
means3D.contiguous().data<float>(),
sh.contiguous().data_ptr<float>(),
colors.contiguous().data<float>(),
opacity.contiguous().data<float>(),
scales.contiguous().data_ptr<float>(),
scale_modifier,
rotations.contiguous().data_ptr<float>(),
cov3D_precomp.contiguous().data<float>(),
viewmatrix.contiguous().data<float>(),
projmatrix.contiguous().data<float>(),
campos.contiguous().data<float>(),
tan_fovx,
tan_fovy,
prefiltered,
out_color.contiguous().data<float>(),
radii.contiguous().data<int>(),
debug);
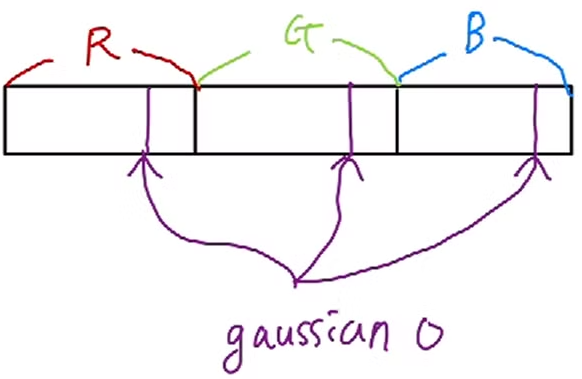
수 많은 함수 인자들 중에, colors.contiguous().data<float>()하나만 보겠습니다.
Gaussian의 파라미터 중 하나인 color의 값이 tensor 형태로 저장이 되어있고, continguous()로 color가 저장된 tensor의 메모리가 연속적임을 보장함과 동시에, .data<float>로 시작주소를 인자로 forward 함수를 호출하고 있습니다.
이렇게 되면 gaussian들의 color가 RGB 순서대로 나열되어있는 1차원 벡터처럼 되게 됩니다.
밑의 그림을 예를 들면 첫 번째 gaussian의 color는 연속적으로 0번째(R) 1번쨰(G) 2번째(B)에 위치하게 되고 두 번째 gaussian의 color는 3번째(R) 4번쨰(G) 5번째(B)에 위치하게 되는 것입니다.

Forward
Forward는 앞의 정보들을 이용해, gaussian들을 복사하고 정렬하고, rendering 하는 과정입니다.
Preprocess--> duplicateWithKeys --> SortPairs -->identifyTileRanges --> Render
- Preprocess: Rendering 때 사용될 정보를 미리 계산
- duplicateWithKeys: 각 타일마다 gaussian을 복사
- SortPairs: Depth별로 radix sort
- identifyTileRanges: 각 타일마다 rendering할 gaussian의 범위 저장
- Render: 이미지 rendering
Preprocess 전에 각 픽셀마다 유용한 정보들이 저장될 메모리 공간을 할당합니다.
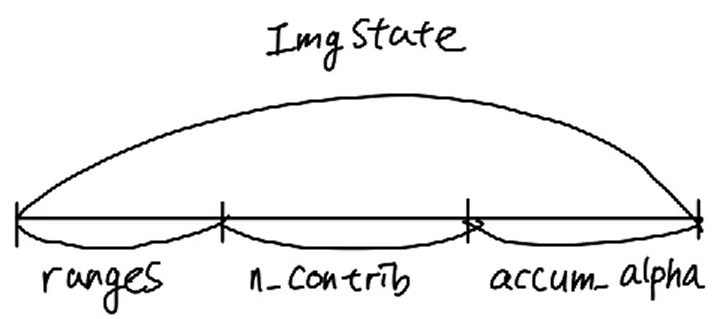
struct ImageState
{
uint2* ranges;
uint32_t* n_contrib;
float* accum_alpha;
static ImageState fromChunk(char*& chunk, size_t N);
};
먼저 ImageState에 대한 구조체가 정의되어있습니다.
ImageState는 rendering될 이미지의 각 픽셀에 저장될 유용한 정보들을 저장합니다.
- ranges: pixel에 누적될 gaussian의 범위
- n_contrib: pixel에 누적될 gaussian 개수
- accum_alpha: pixel에 누적되는 alpha값
size_t img_chunk_size = required<ImageState>(width * height);
char* img_chunkptr = imageBuffer(img_chunk_size);
ImageState imgState = ImageState::fromChunk(img_chunkptr, width * height)
Rendering될 이미지의 width와 height의 크기만큼을 한 size로 정의합니다.
그리고 구조체의 요소들 마다 한 크기(width * height)만큼의 메모리 공간을 확보합니다.
Preprocess
3D 좌표계의 gaussian의 위치를 2D 이미지 좌표의 위치 계산, gaussian이 어느 타일에 겹쳐있는지 계산, gaussian의 opacity가 픽셀마다 얼마나 계산되야 하는지(conic opacity) 등을 계산합니다.
모든 gaussian에 대해서 계산하는 것이 아니고 이미지에 대해 view frustum 안에 있는 gaussian 만을 골라내어 계산합니다.
골라낸 gaussian들 중에서, 3D 좌표계의 covariance를 구하고 이를 2D 좌표계의 covariance를 계산합니다.
const float* cov3D;
if (cov3D_precomp != nullptr)
{
cov3D = cov3D_precomp + idx * 6;
}
else
{
computeCov3D(scales[idx], scale_modifier, rotations[idx], cov3Ds + idx * 6);
cov3D = cov3Ds + idx * 6;
}
// Compute 2D screen-space covariance matrix
float3 cov = computeCov2D(p_orig, focal_x, focal_y, tan_fovx, tan_fovy, cov3D, viewmatrix);
computeCov3D: $\Sigma=RSS^TR^T$
computeCov2D: $\Sigma'=JW\Sigma W^TJ^T$
그리고 EWA algorithm을 통해서 gaussian의 radius를 구하고, 이 radius를 기준으로 gaussian이 어느 타일들과 겹치는지 계산합니다.
또한, gaussian의 중점과 픽셀의 거리마다 opacity가 다르게 적용할 수 있는 conic을 계산합니다.

2D 이미지에 proejction된 gaussian의 중점이 빨간색으로 칠해진 곳이라 가정하고, projection된 범위가 빨간색 실선이라 했을 때, 빨간색 픽셀과 파란색 픽셀은 같은 gaussian이라도 opacity가 다른 값으로 결정이 됩니다.
DuplicateWithKeys
duplicateWithKeys << <(P + 255) / 256, 256 >> > (
P,
geomState.means2D,
geomState.depths,
geomState.point_offsets,
binningState.point_list_keys_unsorted,
binningState.point_list_unsorted,
radii,
tile_grid)
CHECK_CUDA(, debug)
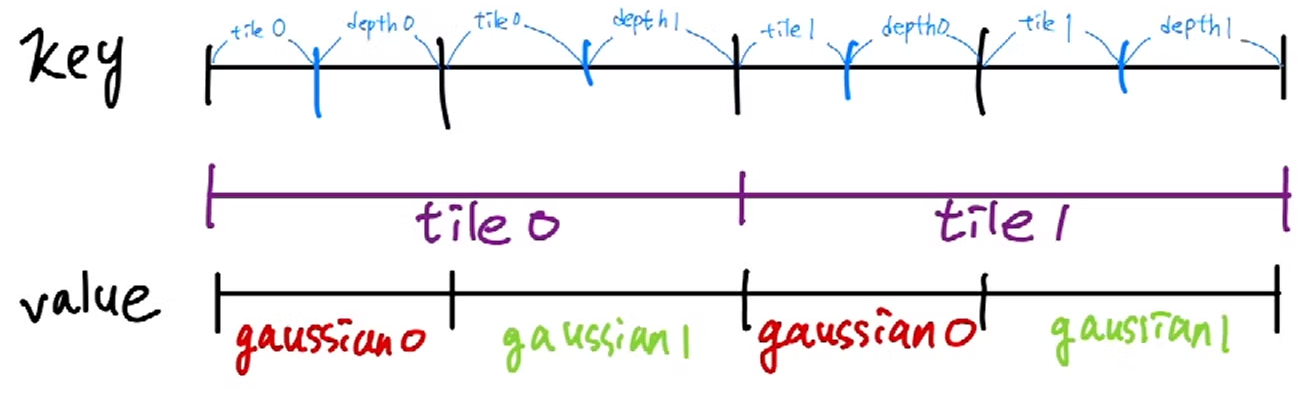
Preprocess에서 계산된 radius를 이용해서, gaussian과 겹친 tile의 id와 depth를 key에 저장합니다.
key는 64bit로 되어 있으며 앞의 32bit는 tile ID, 뒤는 32bit는 depth로 이루어져 있습니다.
한 gaussian 마다 겹쳐진 tile 만큼 복사합니다.
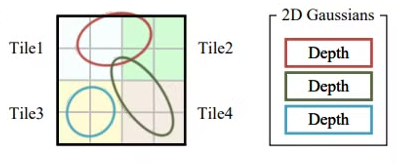
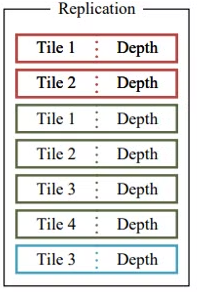
그리고 gaussian의 ID를 value에 저장합니다.
실제로 python의 dictionary처럼 key value가 한 곳에 저장 되는 것은 아니고 key, value가 각각 저장되게 되어있습니다.

그림을 예로 보면 gaussian 0번째가 tile 0과 tile 1이 겹쳐있기 때문에, depth와 tile ID가 함께 key로써 저장합니다.
그리고 value에는 겹친 tile의 개수만큼 gaussian의 ID를 저장합니다.
SortPairs
위에 저장된 key,value를 radix sort를 이용해서 정렬합니다.
결과적으로 각 tile마다 depth 별로 정렬되어 있는 gaussian들이 저장됩니다.

identifyTileranges
위에 정렬된 key,value를 이용하여 각 tile마다 gaussian의 ID의 시작과 끝을 저장합니다.
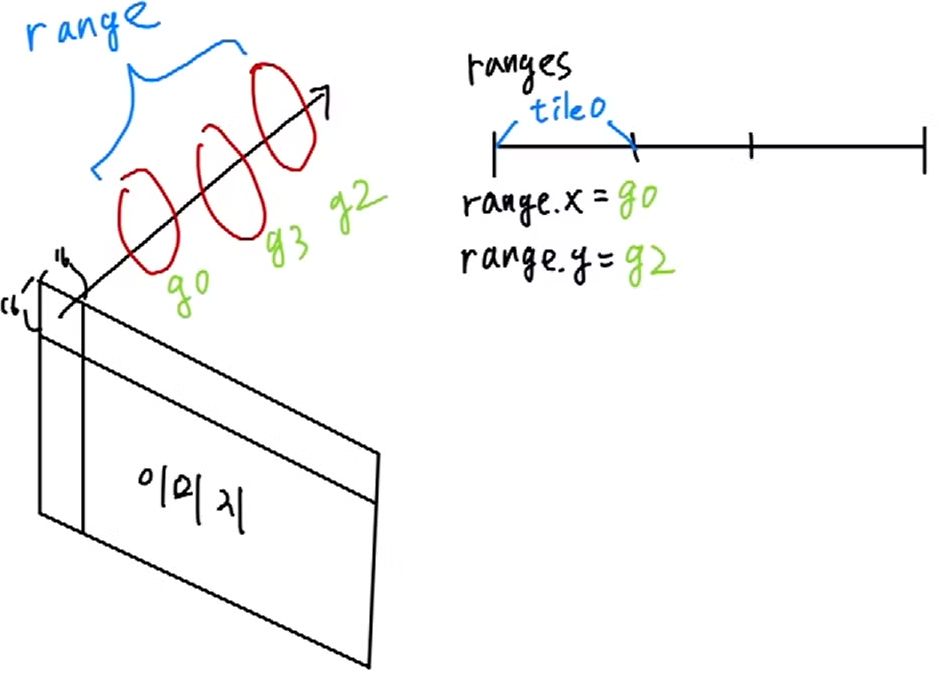
그림을 예로 보면 gaussian 0, gaussian 3, gaussian 2가 tile 0에 겹쳐 있는 상태입니다.
이 때 range는 0번째 위치(tile 0)에 맨 앞 gaussian의 ID를 range.x, 맨 뒤 gaussian의 ID를 range.y에 저장합니다.
이렇게 저장하면 나중에 rendering할 때 range를 이용해서 key, value를 통해 gaussian을 인덱싱을 할 수 있습니다.
Render
Gaussian을 이용해서 이미지를 rendering할 때, CUDA에서 tile마다 grid를 설정하고, tile 안에 pixel마다 thread가 할당됩니다.
그래서 각 thread가 pixel을 병렬적으로 계산되어 빠르게 계산이 됩니다. (사실 이전에 설명한 프로세스 중에서도 병렬로 계산하는 곳이 몇몇 있음)
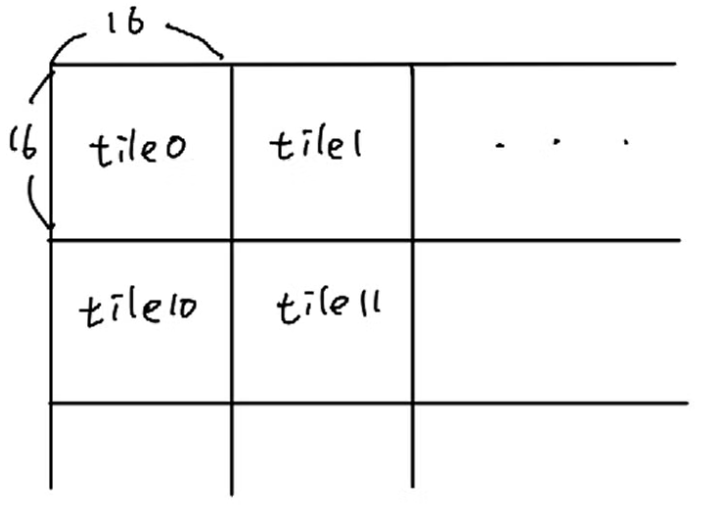

그림의 예로 왼쪽 그림의 tile 0과, tile1은 각각 grid 0, grid 1가 담당하고, 오른쪽 그림은 한 grid안의 16*16=256개의 쓰레드가 각각의 픽셀을 계산을 하게 됩니다.
이제 코드를 살펴보겠습니다.
renderCUDA<NUM_CHANNELS> << <grid, block >> > (
ranges,
point_list,
W, H,
means2D,
colors,
conic_opacity,
final_T,
n_contrib,
bg_color,
out_color);
먼저 renderCUDA라는 커널 함수를 호출하는 부분입니다.
앞서 계산했던 정보들과 gaussian의 파라미터를 인자로 받습니다.
여기서 grid는 tile의 갯수, block은 16*16=256입니다.
auto block = cg::this_thread_block();
uint32_t horizontal_blocks = (W + BLOCK_X - 1) / BLOCK_X;
uint2 pix_min = { block.group_index().x * BLOCK_X, block.group_index().y * BLOCK_Y };
uint2 pix_max = { min(pix_min.x + BLOCK_X, W), min(pix_min.y + BLOCK_Y , H) };
uint2 pix = { pix_min.x + block.thread_index().x, pix_min.y + block.thread_index().y };
uint32_t pix_id = W * pix.y + pix.x;
float2 pixf = { (float)pix.x, (float)pix.y };
// Check if this thread is associated with a valid pixel or outside.
bool inside = pix.x < W&& pix.y < H;
// Done threads can help with fetching, but don't rasterize
bool done = !inside;
// Load start/end range of IDs to process in bit sorted list.
uint2 range = ranges[block.group_index().y * horizontal_blocks + block.group_index().x];
const int rounds = ((range.y - range.x + BLOCK_SIZE - 1) / BLOCK_SIZE);
int toDo = range.y - range.x;
Block의 ID와 thread의 ID를 계산하고, 각 pixel마다 thread별로 계산하도록 위치를 정해줍니다.
그리고 앞서 identifyTileRanges에서 계산한 ranges를 이용해 tile내에 있는 gaussian의 범위를 가져옵니다.
이 때, gaussian의 범위를 가져올 때 thread를 이용해서 gaussian을 병렬적으로 인덱싱을 하게됩니다.
그렇지만 이미 thread는 16*16 = 256 개를 사용하기로 되어 있기 때문에, thread로 한꺼번에 인덱싱해서 가져 올 수 있는 gaussian의 개수는 최대가 256개입니다.
그래서 rounds를 계산해서 256개 이상의 gaussian이 tile 안에 있어도 계속 인덱싱을 해서 가져올 수 있게 합니다.
ex) 300개의 gaussian이 tile 안에 있다면 2번을 수행
__shared__ int collected_id[BLOCK_SIZE];
__shared__ float2 collected_xy[BLOCK_SIZE];
__shared__ float4 collected_conic_opacity[BLOCK_SIZE];
shared 는 grid 내의 각 thread끼리 공유하는 공유 메모리를 할당하는 키워드 입니다.
thread를 이용해서 병렬적으로 tile 안에 있는 gaussian을 인덱싱 했기 때문에 한 grid안에는 같은 gaussian들이 있어야 하기 때문입니다.
그래서 collected_id, collected_xy, collected_conic_opacity는 각각 tile 내에 있는 gaussian들의 정보를 각 thread가 공유하게 됩니다.
for (int i = 0; i < rounds; i++, toDo -= BLOCK_SIZE)
{
// End if entire block votes that it is done rasterizing
int num_done = __syncthreads_count(done);
if (num_done == BLOCK_SIZE)
break;
// Collectively fetch per-Gaussian data from global to shared
int progress = i * BLOCK_SIZE + block.thread_rank();
if (range.x + progress < range.y)
{
int coll_id = point_list[range.x + progress];
collected_id[block.thread_rank()] = coll_id;
collected_xy[block.thread_rank()] = points_xy_image[coll_id];
collected_conic_opacity[block.thread_rank()] = conic_opacity[coll_id];
}
block.sync();
// Iterate over current batch
for (int j = 0; !done && j < min(BLOCK_SIZE, toDo); j++)
{
// Keep track of current position in range
contributor++;
// Resample using conic matrix (cf. "Surface
// Splatting" by Zwicker et al., 2001)
float2 xy = collected_xy[j];
float2 d = { xy.x - pixf.x, xy.y - pixf.y };
float4 con_o = collected_conic_opacity[j];
float power = -0.5f * (con_o.x * d.x * d.x + con_o.z * d.y * d.y) - con_o.y * d.x * d.y;
if (power > 0.0f)
continue;
// Eq. (2) from 3D Gaussian splatting paper.
// Obtain alpha by multiplying with Gaussian opacity
// and its exponential falloff from mean.
// Avoid numerical instabilities (see paper appendix).
float alpha = min(0.99f, con_o.w * exp(power));
if (alpha < 1.0f / 255.0f)
continue;
float test_T = T * (1 - alpha);
if (test_T < 0.0001f)
{
done = true;
continue;
}
// Eq. (3) from 3D Gaussian splatting paper.
for (int ch = 0; ch < CHANNELS; ch++)
C[ch] += features[collected_id[j] * CHANNELS + ch] * alpha * T;
T = test_T;
// Keep track of last range entry to update this
// pixel.
last_contributor = contributor;
}
}
이 때 현재 pixel의 위치와 gaussian의 위치 간의 차이를 계산하고, 그 계산한 결과에 conic_opacity를 적용하여, 최종적으로 pixel에 대한 opacity를 계산합니다.
그리고 일정 조건이 맞는 gaussian들만 사용하게 됩니다.
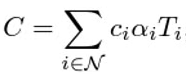

그리고 논문에 나온 alpha blending 식을 이용해서, 한 pixel에 대한 color를 계산합니다.
이 때 gaussian의 color가 저장된 메모리로부터 gaussian의 ID를 이용해 color 값을 인덱싱을 합니다.
예를 들어 한 pixel에 gaussian 0번이 사용되어 color가 계산될 때 color tensor에서 인덱싱합니다.
이 과정을 tile안에 있는 gaussian 마다 반복합니다.
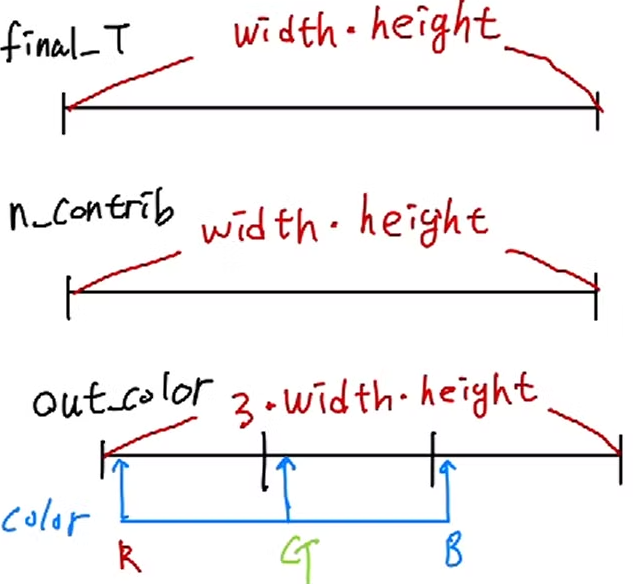
이제 각 pixel 별로 계산한 정보들을 저장합니다.
if (inside)
{
final_T[pix_id] = T;
n_contrib[pix_id] = last_contributor;
for (int ch = 0; ch < CHANNELS; ch++)
out_color[ch * H * W + pix_id] = C[ch] + T * bg_color[ch];
}
- final_T : pixel에 누적된 opacity
- n_contrib: pixel에 계산된 gaussian의 개수
- out_color: pixel에 계산된 color (최종적으로 rendering된 이미지가 됨)
여기까지가 rasterization의 forward 부분입니다.
설명한다고 그림까지 그렸는데 알아보기가 힘들 수도 있을 것 같습니다( 악필의 눈물)
다음에는 backward 부분 설명해보겠습니다.
'AI > 3DGS' 카테고리의 다른 글
| [3DGS] SplaTAM: Splat, Track & Map 3D Gaussians for Dense RGB-D SLAM [CVPR 2024] (2) | 2024.06.18 |
|---|---|
| [3DGS] Gaussian Splatting SLAM [CVPR 2024] (5) | 2024.06.17 |
| [논문리뷰] 3D Gaussian Splatting (7) | 2024.01.10 |